







Summary: in this tutorial, you will learn how to delete duplicate rows from a table in SQL Server.
To delete the duplicate rows from the table in SQL Server, you follow these steps:
- Find duplicate rows using
GROUP BYclause orROW_NUMBER()function. - Use
DELETEstatement to remove the duplicate rows.
Let’s set up a sample table for the demonstration.
Setting up a sample table
First, create a new table named sales.contacts as follows:
DROP TABLE IF EXISTS sales.contacts;
CREATE TABLE sales.contacts(
contact_id INT IDENTITY(1,1) PRIMARY KEY,
first_name NVARCHAR(100) NOT NULL,
last_name NVARCHAR(100) NOT NULL,
email NVARCHAR(255) NOT NULL,
);
Second, insert some rows into the sales.contacts table:
INSERT INTO sales.contacts
(first_name,last_name,email)
VALUES
('Syed','Abbas','syed.abbas@example.com'),
('Catherine','Abel','catherine.abel@example.com'),
('Kim','Abercrombie','kim.abercrombie@example.com'),
('Kim','Abercrombie','kim.abercrombie@example.com'),
('Kim','Abercrombie','kim.abercrombie@example.com'),
('Hazem','Abolrous','hazem.abolrous@example.com'),
('Hazem','Abolrous','hazem.abolrous@example.com'),
('Humberto','Acevedo','humberto.acevedo@example.com'),
('Humberto','Acevedo','humberto.acevedo@example.com'),
('Pilar','Ackerman','pilar.ackerman@example.com');
Third, query data from the sales.contacts table:
SELECT contact_id, first_name, last_name, email FROM sales.contacts;
The following picture shows the output of the query:
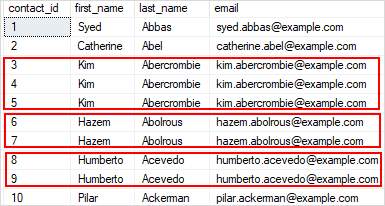
There are many duplicate rows (3,4,5), (6,7), and (8,9) for the contacts that have the same first name, last name, and email.
Delete duplicate rows from a table example
The following statement uses a common table expression (CTE) to delete duplicate rows:
WITH cte AS (
SELECT
contact_id,
first_name,
last_name,
email,
ROW_NUMBER() OVER (
PARTITION BY
first_name,
last_name,
email
ORDER BY
first_name,
last_name,
email
) row_num
FROM
sales.contacts
)
DELETE FROM cte
WHERE row_num > 1;
In this statement:
- First, the CTE uses the
ROW_NUMBER()function to find the duplicate rows specified by values in thefirst_name,last_name, andemailcolumns. - Then, the
DELETEstatement deletes all the duplicate rows but keeps only one occurrence of each duplicate group.
SQL Server issued the following message indicating that the duplicate rows have been removed.
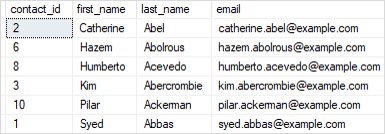
If you query data from the sales.contacts table again, you will find that all duplicate rows are deleted.
SELECT contact_id,
first_name,
last_name,
email
FROM sales.contacts
ORDER BY first_name,
last_name,
email;
In this tutorial, you have learned how to delete duplicate rows from a table in SQL Server.
from WordPress https://ift.tt/38307Ch
via IFTTT




0 comments:
Post a Comment